Warnung
Es ist sehr einfach in einem stochastische Modell Feher zu machen. Hier sind nur meine vorläufigen Ergebnisse.
Problem
Wie kann OSEG entscheiden ein Projekt zu unterstützen oder nicht?
Die Antwort ist doch klar: wir nutzen unser gesamtes Wissen – wir machen eine Umfrage. Nun sind nicht alle Menschen Experten in Allem. Wie machen wir diese Umfrage so geschickt, dass die Antwort möglichst richtig ist? Diese Frage möchten wir hier beantworten.
Unswer Hauptwerkzeug ist mathematische Modellierung mit sehr einfachen Modellen. Auch wenn die Realität sehr komplex ist, können wir aus einfachen Beispielen viel lernen.
Hintergrund
Diese Aufgabe entstand während des Hackathons 2019. Eine Gruppe von OSEG soll entscheiden ob OSEG ein Projekt mit offiziell unterstüzt. Moe hat ein Verfahren vorgeschlagen: Umfrage von OSEG nicht Experten, OSEG Experten und speizeillen OSEG Leuten damit alles rechtlich korrekt ist.
Ich werde hier mein naives mathematisches Modell dazu erstellen. Es ist naiv, weil ich kein Experte auf diesem Gebiet bin – welch eine Ironie 😬. Ich werde hier zuerst meine Fragen und Annahmen sammeln und dann gucken, was Profis dazu sagen.
Mathematisches Modell
Unser Problem soll möglichst einfach sein. Wir gehen von  Menschen aus. Alle diese Menschen haben unterschiedlichen Wissenstand. Sie müssen eine Frage mit "ja" oder "nein" beantworten. Diese Antwort kann objektiv korrekt oder falsch sein. Wir müssen diese Antworten so schlau kombinieren, dass unser Ergebnis so korrekt wie möglich ist.
Menschen aus. Alle diese Menschen haben unterschiedlichen Wissenstand. Sie müssen eine Frage mit "ja" oder "nein" beantworten. Diese Antwort kann objektiv korrekt oder falsch sein. Wir müssen diese Antworten so schlau kombinieren, dass unser Ergebnis so korrekt wie möglich ist.
Mensch
Wir modellieren jeden Menschen durch eine Zufallsvariable  ,
,  . Jeder Mensch beantwortet eine Frage mit "ja" oder "nein". Das bedeutet
. Jeder Mensch beantwortet eine Frage mit "ja" oder "nein". Das bedeutet  . Wir nehmen an, dass die Menschen, die Fragen unabhänging von einenader beantworten.
. Wir nehmen an, dass die Menschen, die Fragen unabhänging von einenader beantworten.
Wirklichkeit
Wir modellieren die Wirklichkeit, als eine Zufallsvariable  . Sie repräsentiert die richtige Antwort "ja" oder "nein". Bevor wir Menschen fragen, haben wir überhaupt keine Ahnung, was die richtige Antwort ist, daher gilt für die Wahrscheinlichkeit
. Sie repräsentiert die richtige Antwort "ja" oder "nein". Bevor wir Menschen fragen, haben wir überhaupt keine Ahnung, was die richtige Antwort ist, daher gilt für die Wahrscheinlichkeit  .
.
Wissen
Jeder Mensch hat unterschiedliches Wissen. Das drücken wir durch unterschiedliche Wahrscheinlichkeiten, die richtige Antwort zu erraten

Hier haben wir gleichzeitig angenommen, dass der Mensch gleich gut eine "nein"- und eine "ja"-Antwort erraten kann.
Weil die Menschen unabhängig von einenader die Frage beantworten, gilt für jede Untermenge[1] 

Entscheidung basierend auf einer Umfrage
Unsere Entscheidung ist eine Funktion  .
.
- Parametren

- Sie hängt von den Menschen Entscheidungen (x_1,\ldots,x_n) "ja" oder "nein".
- Einem Münzenwurf
 , wenn sie unentschieden ist.
, wenn sie unentschieden ist.
![{\displaystyle {\begin{array}{rrcl}f&:[0,1]^{n}\times {\{ja,nein}\}^{(n+1)}&\longrightarrow &\{ja,nein\}\\&(p_{1},\ldots ,p_{n},x_{1},\ldots ,x_{n},m)&\mapsto &f(p_{1},\ldots ,p_{n},x_{1},\ldots ,x_{n},m)\end{array}}}](https://wikimedia.org/api/rest_v1/media/math/render/svg/9cd8fcebc1b8a5e3060eb7d0c7123b143c4b21d1)
Die Entscheidungen aller Menschen können wir mit einer Menge  ausdrücken. Diese Menge enthält alle Indizes, die die Frage mit "ja" beantwortet haben. Das Komplement dieser Menge
ausdrücken. Diese Menge enthält alle Indizes, die die Frage mit "ja" beantwortet haben. Das Komplement dieser Menge  in
in  representiert die "nein"-Entscheidungen.
representiert die "nein"-Entscheidungen.
Mathematische Lösung
Nachdem alle Menschen ihre Antworten gegeben haben, können wir berechnen mit welcher Wahrscheinlichkeit die Reailtät auch mit "ja" antwortet:

Mit Bayes Formula gilt

Wir kürzen überall  , dann gilt
, dann gilt

Dadurch, dass die Menschen unabhängign von einander die Etscheidungen treffen, gilt:

Jetzt setzen wird die definierten Wahrscheinlichkeiten für richtige Antworten  und damit Wahrscheinlichkeiten für falsche Antworten
und damit Wahrscheinlichkeiten für falsche Antworten  ein und erhalten
ein und erhalten

Die Wahrscheinlickeit, dass die richtige Antwort "nein" ist, ist dann das Gegenereignis:

Uns interessiert, ob diese Wahrscheinlichkeit größer ist als die Wahrscheinlichkeit für eine falsche Antwort. Das ist

Also wenn gilt

Unsere Entscheidungsfunktion ist somit:

Interpretation der Lösung
Intuitive Ergebnisse
Viele Ergebnisse aus dem Modell sind intuitiv. Das ist schön - sie zeigen, dass das Model plausibel ist. Doch vorsichtig! Vetraue nie deiner Intuition bei der Lösung der stochastischen Problemen. Stochastik ist kontraintuitiv, desswegen muss man alle Ergebnisse formal begründen. Hier sind diese Ergebnisse:
"Wenn man nur begrenze Anzahl der Personen befragen kann, frag die schlauesten Menschen."
TODO: formale Begründung aufschreiben.
"Frag soviele Menschen wie möglich".
TODO: Formale Begründung aufschreiben.
Wenig intuitive Ergebnisse
"Wer häufig daneben liegt, ist ein Experte! Fragt ihn/sie und tu das Gegenteil."
Begründung  ist genau dann maximal wenn
ist genau dann maximal wenn  minimal ist.
minimal ist.
"Manchmal weiß eine Person mit viel Erfahrung weniger als zwei Personen mit wenig Erfahrung."
"Manchmal weiß eine Person mit viel Erfahrung mehr als zwei Persone nmit wenig Erfahrung."
Wir nummerieren die Menschen mit 1 für viel Erfahrung und 2, 3 mit wenig Erfahrung. Wir befragen sie. Wenn 1 sagt "Ja" aber 2 und 3 sagen "nein", wir wählen "ja" nur wenn

Wenn zwei weniger Erfahrene haben gleiche Erfolgrswahrscheinlichkeiten  gilt für die obere Formel:
gilt für die obere Formel:

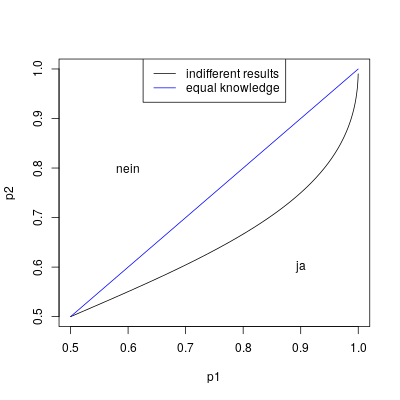
Der Graph unten zeigt, wenn die Meinung "ja" der ersten Person, ist "gleich wichtig" als die Meinungen "nein" der anderen beiden Personen. Das sind alle Punkten unterhalb der Linie.
Die gerade blaue Linie, zeigt, wenn alle gleiches Wissen haben

. Man kann aus diesem Graph schlussfolgern:
- Wenn ein wirklich guter Experte (
 sehr nah an 1) "ja" sagt, dann muss man wirklich gut sein (
sehr nah an 1) "ja" sagt, dann muss man wirklich gut sein ( und
und  auch nahe 1) und diese Meinung mit "nein" überstimmen.
auch nahe 1) und diese Meinung mit "nein" überstimmen.
- Wenn man kein wirklich guter Experte ist ( nicht nah an 1) und sagt "ja", dann reichen zwei weniger Erfahrene aus, um diese Antwort mit "nein" zu überstimmen.
Implementatierung
R implementatirung
# "Yes" is 1, "No" is 0.
decide<-function(p, w){
# p are probabilities for correct answer.
# x are results of a survey.
# Invert x when p < 1/2.
x[p<0.5]<-!x[p<0.5]
if(result_consitant(p,x)){
m <- rbinom(10, 1, prob=0.5)
return(f(p,x, m))
}else{
stop("Inconsistant results: two different answers are possible.")
}
}
result_consitant<-function(p,x){
# A reasult is NOT consitant, when two persons who are always right but
# give different answers
sure_events = unique(x[p]==1)
return (length(sure_events)<=1)
}
f<-function(p,x,m){
pos<-positive(x,p)
if(pos > 0.5){
return(1)
}else if(pos < 0.5){
return(0)
}else{
return(m)
}
}
positive<-function(x,p){
# Return probability for the positive_answer.
a <- prod(p[x])*prod((1-p)[!x])
b <- prod((1-p)[x])*prod(p[!x])
return(a/(a+b))
}
p <- c(0.9, 0.7, 0.7)
x <- c(1,0,0) # Opinions are "Yes", "No", "No".
decide(p, x) # Decision is "Yes".
p <- c(0.84, 0.7, 0.7)
decide(p, x) # Decision is "No".
Referenzen
Youtube Kanal von Nikolai Osipov (Николай Николаевич Осипов), über kollektive Intelligenz. https://www.youtube.com/channel/UCuH_xeNX7KKIYHeZXaPO_OA
Notizen
"ja" und "nein" vs "richtig" und "falsch"
Mein erstes Modell war nicht mit "ja" und "nein" sondern mit "richtig" und "falsch". Dieses Modell verleiht dazu, eine Entscheidungsfunktion zu konstruieren die immer "richtig" ist, ohne die Antworten von Experten zu berücksichtigen. Das ist zu unrealistisch. Ich werde später mir dieses Modell nochmal ansehen und Zusammenhang zu dem "ja"-"nein"-Modell analysieren.
- ↑ Ich wähle eine Untermenge, weil man in Wahrscheinlichkeitstheorie zwischen einer Unabhängigkeit und einer paarweisen Unabhängigkeit unterscheiden muss. Es ist ausreichend, nurdie "ja" Antworten zu betrachten, weil es ist ein Erzeuger von der
 -Algebra erzeugt durch alle
-Algebra erzeugt durch alle  bedingt durch
bedingt durch  bzw.
bzw.  .
.
